

神经网络是什么?
神经网络是一组受人类大脑功能启发的算法。一般来说,当你睁开眼睛时,你看到的东西叫做数据,再由你大脑中的 Nuerons(数据处理的细胞)处理,并识别出你周围的东西,这也是神经网络的工作原理。神经网络有时被称为人工神经网络(Artificial Neural Network,ANN),它们不像你大脑中的神经元那样是自然的,而是人工模拟神经网络的性质和功能。
神经网络的组成?
人工神经网络是由大量高度相互关联的处理单元(神经元)协同工作来解决特定问题。首先介绍一种名为感知机的神经元。感知机接收若干个输入,每个输入对应一个权重值(可以看成常数),产出一个输出。
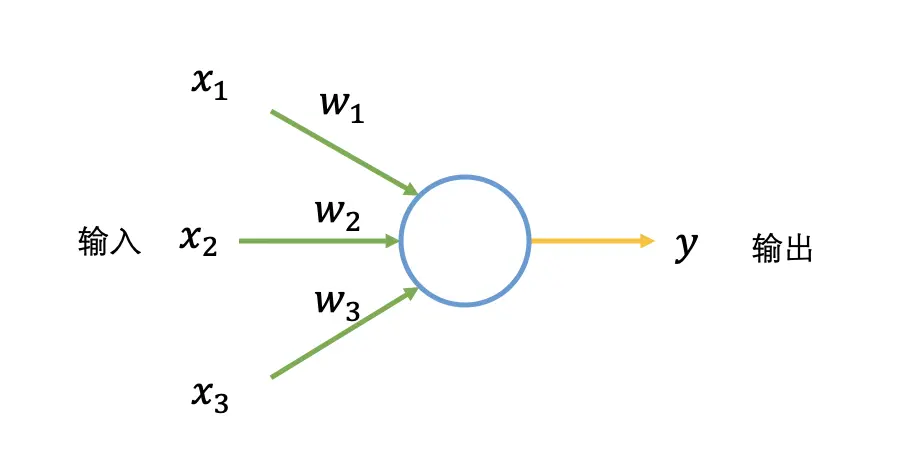
接下来用一个生活中的例子形象理解感知机,假设一个场景,周末去爬山,有以下三种输入(可以理解为影响因素):
- 男/女朋友是否陪你去;
- 天气是否恶劣;
- 距离登山地点是否方便;
对于你来说,输入(2)影响非常大,这样就设置的权重值就大,输入(3)的影响的比较小,权重值就小。
再将输入二值化,对于天气不恶劣,设置为 1(),对于天气恶劣,设置为 0(),天气的影响程度通过权重值体现,设置为 10()。同样设置输入(1)的权值为 8(),输入(3)的权重值为 1()。输出二值化是去爬山为 1(),不去为 0()。
假设对于感知机,如果 的结果大于某阈值(如 5),表示去爬山 ,随机调整权重和阈值,感知机的结果会不一样。
一个典型的神经网络有成百上千个神经元(感知机),排成一列的神经元也称为单元或是层,每一列的神经元会连接左右两边的神经元。感知机有输入和输出,对于神经网络是有输入单元与输出单元,在输入单元和输出单元之间是一层或多层称为隐藏单元。一个单元和另一个单元之间的联系用权重表示,权重可以是正数(如一个单元激发另一个单元) ,也可以是负数(如一个单元抑制或抑制另一个单元)。权重越高,一个单位对另一个单位的影响就越大。
神经网络如何工作?
神经网络的工作大致可分为前向传播和反向传播,类比人们学习的过程,前向传播如读书期间,学生认真学习知识点,进行考试,获得自己对知识点的掌握程度;反向传播是学生获得考试成绩作为反馈,调整学习知识的侧重点。
以下展示了 2 个输入和 2 个输出的神经网络: 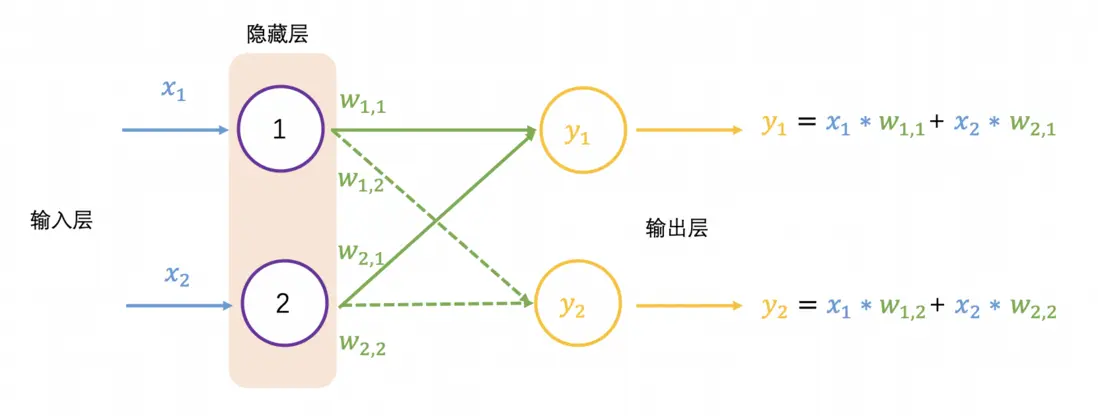
前向传播对应的输出为 和 ,换成矩阵表示为
以上 矩阵每行数乘以 矩阵每列数是矩阵乘法,也称为点乘(dot product)或内积(inner product)。
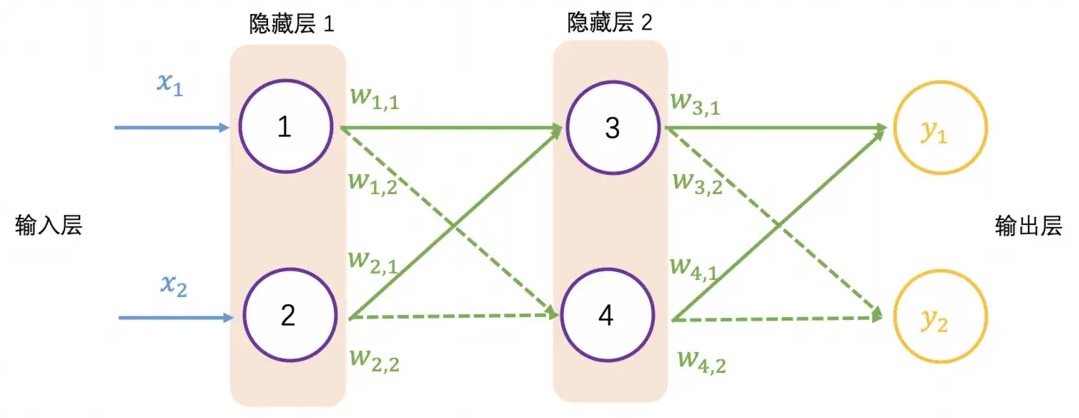
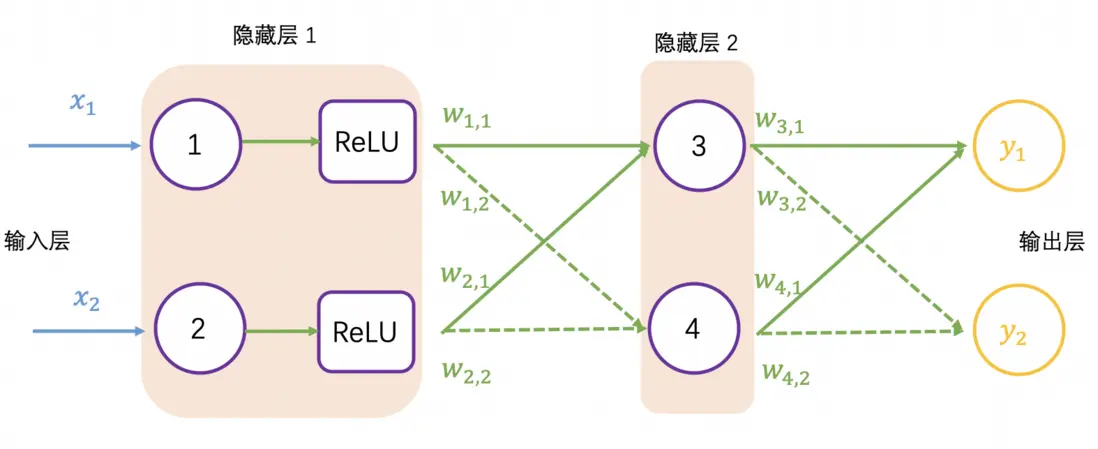
继续增加一层隐藏层,如下图所示,并采用矩阵乘法表示输出结果,可以看到一系列线性的矩阵乘法,其实还是求解 4 个权重值,这个效果跟单层隐藏层的效果一样:
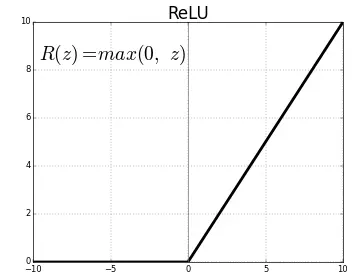
大多数真实世界的数据是非线性的,我们希望神经元学习这些非线性表示,可以通过激活函数将非线性引入神经元。例如爬山例子中的阈值,激活函数 ReLU(Rectified Linear Activation Function)采用阈值 0,输入大于 0,输出为输入值,小于 0 输出值为 0,公式表示为 ,ReLU 的图像如下所示。
加入激活函数的神经网络如下图所示:
再以爬山为例,输出值 表示去爬山, 表示不去爬山,在生活中会用概率表述爬山的可能性,这里通过 SoftMax 函数规范输出值,公式如下。
输出值 和 的计算过程如下,可以看到爬山的概率是 98%:
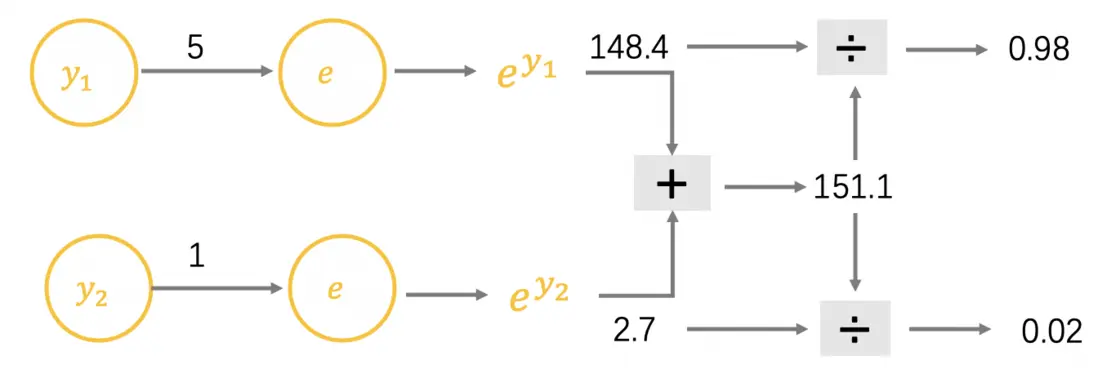
加入 SoftMax 函数的神经网络如下图所示:

获得神经网络的输出值 (0.98, 0.02) 之后,与真实值 (1, 0) 比较,非常接近,仍然需要与真实值比较,计算差距(也称误差,用 表示),就跟摸底考试一样,查看学习的掌握程度,同样神经网络也要学习,让输出结果无限接近真实值,也就需要调整权重值,这里就需要反向传播了。
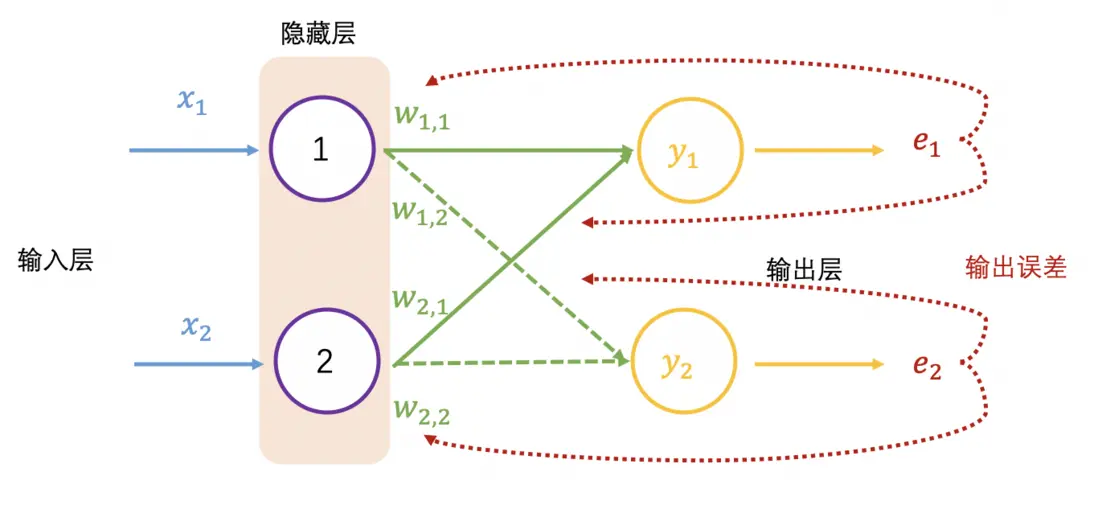
在反向传播过程中需要依据误差值来调整权重值,可以看成参数优化过程,简要过程是,先初始化权重值,再增加或减少权重值,查看误差是否最小,变小继续上一步相同操作,变大则上一步相反操作,调整权重后查看误差值,直至误差值变小且浮动不大。
现在以简单的函数 为例, 表示误差,我们希望找到 ,最小化 ,函数展示如下。红色点是随机的初始点类比权重值的初始化,左边是当 增大时,误差是减小;右边是当 减小时,误差是减小。如何找到误差下降的方向成为了关键。
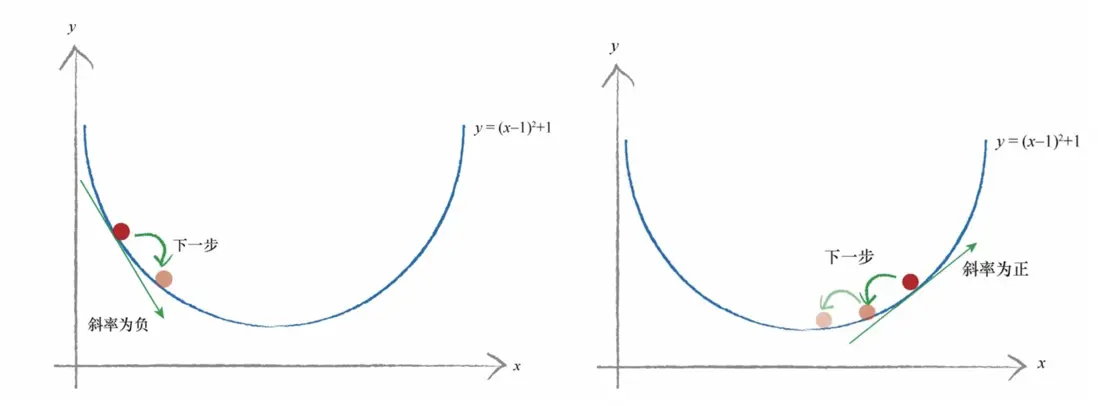
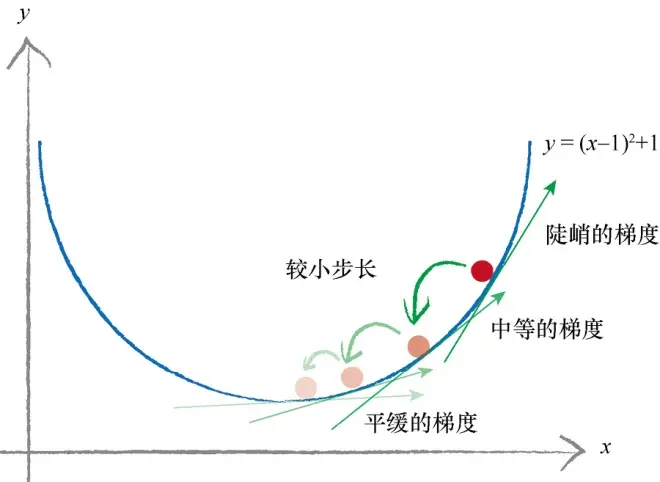
斜率的大小表明变化的速率,意思是当斜率比较大的情况下,权重 变化所引起的结果变化也大。把这个概念引入求最小化的问题上,以权重导数乘以一个系数作为权重更新的数值,这个系数我们叫它学习率(learning rate),这个系数能在一定程度上控制权重自我更新,权重改变的方向与梯度方向相反,如下图所示,权重的更新公式是 。
由于误差是目标训练值与实际输出值之间的差值,即 ,表示为 ,导数为:
经过反复迭代,让损失函数值无限接近 0,浮动不大时,获得合适的权重,即神经网络训练好了。
本文用生动形象语言的介绍了神经网络的基本结构及数学原理,为了方便大家理解,本文的参数围绕着 ,后续继续深入学习,若遇到其他参数,如 ,不用感到陌生,解决思路跟 类似。
好了,祝大家有所进步!