背景
之前介绍过小微企业电子合同防篡改实现,手动操作有些繁琐,能否做成自动化脚本?
功能
- pdf 导出jpg
- jpg 转pdf
- 所有者权限控制
- 数字签名
实现
上面4个功能,每个功能的实现可以有多种工具,但是能够全部实现的却没找到。只能结合多个工具来实现。
java 实现
继续阅读“python 自动化pdf数字证书签名”java 平台只能实现 1 2 3/4 功能,3和4只能选择一个

xuenhua’s 站点

之前介绍过小微企业电子合同防篡改实现,手动操作有些繁琐,能否做成自动化脚本?
上面4个功能,每个功能的实现可以有多种工具,但是能够全部实现的却没找到。只能结合多个工具来实现。
继续阅读“python 自动化pdf数字证书签名”java 平台只能实现 1 2 3/4 功能,3和4只能选择一个
张量是一种特殊的数据结构,与数组和矩阵非常相似。在 PyTorch 中,我们使用张量来编码模型的输入和输出,以及模型的参数。
张量类似于 NumPy 的 ndarray,不同之处在于张量可以在 GPU 或其他硬件加速器上运行。实际上,张量和 NumPy 数组通常可以共享底层内存,从而无需复制数据(详见与 NumPy 的桥接)。张量还针对自动微分进行了优化(我们将在后面的 Autograd 部分详细介绍)。如果您熟悉 ndarrays,您会很快适应 Tensor API。如果不熟悉,请继续阅读!
import torch
import numpy as np
初始化张量
张量可以通过多种方式进行初始化。请看以下示例
直接从数据创建
张量可以直接从数据创建。数据类型会自动推断。
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)
从 NumPy 数组创建
张量可以从 NumPy 数组创建(反之亦然 – 详见与 NumPy 的桥接)。
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
在Python中,字符串是一种常见的数据类型,用于表示文本信息。除了普通的字符串,Python还提供了一些特殊的字符串前缀和格式化字符串,包括r’ ‘,b’ ‘,u’ ‘,f’ ‘。本文将详细解释这些前缀的含义以及它们的用法,以帮助大家更好地理解和应用它们。
更多Python学习内容:http://ipengtao.com
r’ ‘: 原始字符串
r前缀表示原始字符串(raw string),它会取消字符串中的转义字符(如\n、\t)的特殊含义。原始字符串适用于需要保留转义字符原始形式的情况,如正则表达式、文件路径等。
1 基本用法
# 使用r前缀创建原始字符串
path = r’C:\Users\Username\Documents’
print(path)
在上述示例中,r前缀将字符串中的反斜杠\视为普通字符,而不是转义字符。
2 与转义字符的比较
# 普通字符串与原始字符串的比较
normal_str = ‘C:\\Users\\Username\\Documents’
raw_str = r’C:\Users\Username\Documents’
print(normal_str == raw_str) # 输出 True
原始字符串与普通字符串在表示相同的文本时是相等的,但原始字符串更容易阅读和维护。
b’ ‘: 字节字符串
b前缀表示字节字符串(bytes string),它用于处理二进制数据,而不是文本数据。字节字符串是不可变的,通常用于处理图像、音频、网络协议等二进制数据。
1 基本用法
# 使用b前缀创建字节字符串
binary_data = b’\x48\x65\x6c\x6c\x6f’ # 字母 ‘Hello’ 的字节表示
print(binary_data)
在上述示例中,b前缀表示字节字符串,每个\x后面跟着两个十六进制数字,表示一个字节。
2 字符串与字节字符串的区别
# 字符串与字节字符串的区别
text = ‘Hello’
binary_data = b’Hello’
print(type(text)) # 输出 <class ‘str’>
print(type(binary_data)) # 输出 <class ‘bytes’>
字符串和字节字符串是不同的数据类型,字符串用于文本,字节字符串用于二进制数据。
u’ ‘: Unicode字符串
u前缀表示Unicode字符串,它用于处理Unicode编码的文本数据。在Python 3中,所有的字符串都是Unicode字符串,因此很少需要使用u前缀。在Python 2中,u前缀用于表示Unicode字符串。
1 基本用法
# 使用u前缀创建Unicode字符串(Python 2示例)
unicode_text = u’你好,世界!’
print(unicode_text)
在Python 3中,无需使用u前缀,普通字符串即为Unicode字符串。
2 Unicode字符串与普通字符串的区别
# Unicode字符串与普通字符串的区别(Python 2示例)
text = ‘Hello’
unicode_text = u’Hello’
print(type(text)) # 输出 <type ‘str’>
print(type(unicode_text)) # 输出 <type ‘unicode’>
在Python 2中,Unicode字符串与普通字符串是不同的数据类型,用于区分文本编码。
f’ ‘: 格式化字符串
f前缀表示格式化字符串(formatted string),它用于在字符串中嵌入表达式的值。在格式化字符串中,可以使用大括号{}来引用变量或表达式,并将其值插入字符串中。
1 基本用法
# 使用f前缀创建格式化字符串
name = ‘Alice’
age = 30
greeting = f’Hello, my name is {name} and I am {age} years old.’
print(greeting)
在上述示例中,f前缀表示格式化字符串,大括号{}内的表达式会被计算并插入到字符串中。
2 表达式和变量
# 在格式化字符串中使用表达式和变量
x = 10
y = 20
result = f’The sum of {x} and {y} is {x + y}’
print(result)
格式化字符串允许嵌入表达式和变量,并将它们的值动态插入到字符串中。
总结
在Python中,r’ ‘,b’ ‘,u’ ‘,f’ ‘等前缀和格式化字符串是用于处理不同类型文本和数据的工具。r前缀表示原始字符串,b前缀表示字节字符串,u前缀表示Unicode字符串,f前缀表示格式化字符串。了解这些前缀的含义和用法有助于更好地处理不同类型的字符串和数据。
相对导入只能用于同一个package里,并且包内的文件不能单独运行,只能在包的外部来调用
|--testmodule.py
|
|--testpy
|
|-- __init__.py 模块标志文件
|
|-- hello.py 模块1
|
|-- test.py 模块2,导入模块1,不可以单独运行
|
|-- test2.py 可以单独运行
hello.py
print('hello.py')
class hhh():
print('hhhh')
test.py
from .hello import hhh
print('test.py')
testmodule.py
from testpy import test
print('OK')
python3 testmodule.py
hello.py
hhhh
test.py
OK
test2.py
from hello import hhh
print('test2.py')
cd testpy
ls
__init__.py __pycache__ hello.py test.py test2.py
python3 test.py 不可以单独运行
Traceback (most recent call last):
File "/Users/yourname/Documents/testpy/test.py", line 1, in <module>
from .hello import hhh
ImportError: attempted relative import with no known parent package
python3 test2.py 可以单独运行
hello.py
hhhh
test2.py
声明:python,cx_Oracle和instantclient的版本应一致
我这里使用的版本是python3.6 64位 ,cx_Oracle-5.3-11g.win-amd64-py3.6-2和instantclient-basic-windows.x64-18.5.0.0.0dbru
1. 首先安装cx_Oracle包
尽量不要直接使用pip install cx_Oracle,这样默认安装的是最新版本的cx_Oracle,可能会出现以下错误
1.1 cx_Oracle 报错:cx_Oracle.DatabaseError: DPI-1050: Oracle Client library must be at version 11.2
解决方法:从 https://pypi.python.org/pypi/cx_Oracle/5.3 下载低版本cx_Oracle版本 可以下载cx_Oracle-5.3-11g.win-amd64-py3.6-2.exe ,然后直接安装
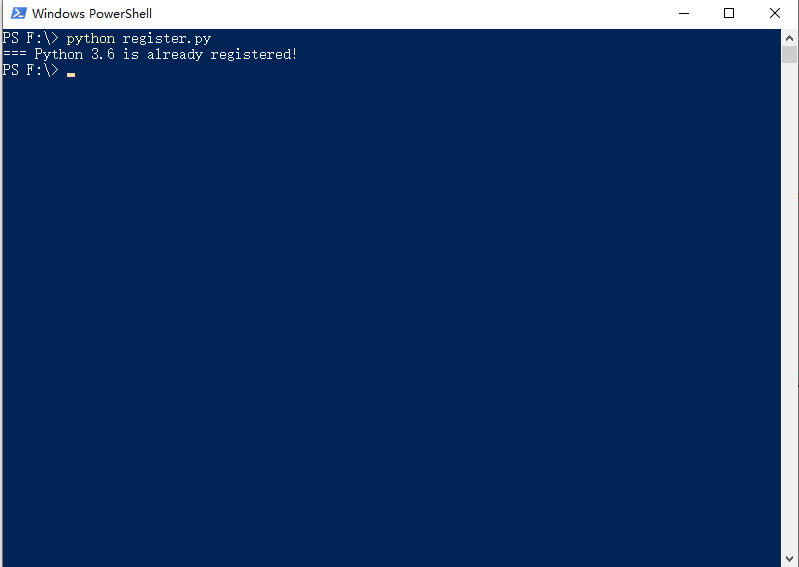
1.2 如果在安装cx_Oracle-5.3-11g.win-amd64-py3.6-2.exe 时提示Python version 3.6 required, which was not found in the registry
可以通过执行这个文件来解决
register.py 链接: https://pan.baidu.com/s/1GcPK_I7ddSLZkM2sv7AHtA 提取码: qrwm
2. 下载instantclient-basic-windows.x64-11.2.0.4.0.zip,解压并配置环境变量(放到path中)
下载地址:https://www.oracle.com/technetwork/cn/topics/winx64soft-101515-zhs.html
下载好后解压,并配置环境变量
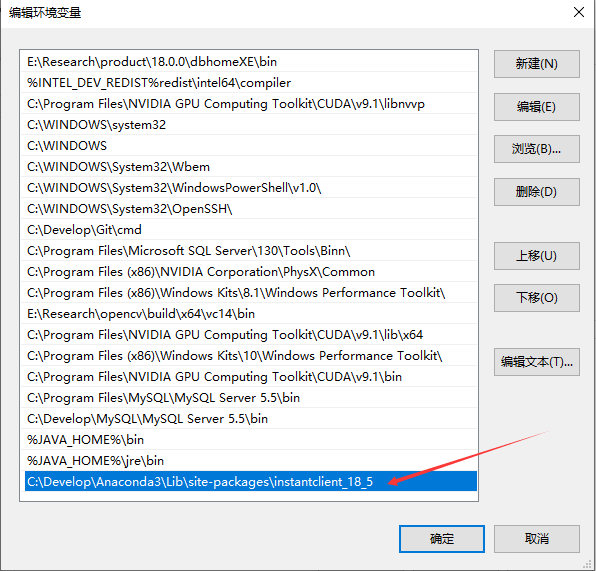
3. 将instantclient下所有.dll文件到python\Lib\site-packages\下(我这里的路径为C:\Develop\Anaconda3\Lib\site-packages)
4. 测试代码如下
import cx_Oracle conn=cx_Oracle.connect('username','password','172.16.5.29:1521/ORCL') cursor=conn.cursor() print("连接成功!") cursor.close() conn.commit() conn.close()当你看到“连接成功”的提示语句时,那么就恭喜你成功了用python连上了oracle数据库
完成这个任务的整体流程,具体步骤如下:
步骤1 连接到MySQL数据库
步骤2 执行SQL查询语句
步骤3 获取查询结果
步骤4 提取相应字段的值
接下来,我将逐个步骤详细说明。
步骤1:连接到MySQL数据库
首先,我们需要安装Python的MySQL驱动程序。在命令行中运行以下命令安装驱动程序:
pip install mysql-connector-python #mysql-connector已经过期
接下来,在Python脚本中引入MySQL驱动程序,并使用connect()函数连接到MySQL数据库。你需要提供数据库的相关信息,例如主机名、用户名、密码和数据库名称。
import mysql.connector
# 连接到MySQL数据库
cnx = mysql.connector.connect(
host=”localhost”,
user=”yourusername”,
password=”yourpassword”,
database=”yourdatabase”
)
步骤2:执行SQL查询语句
一旦成功连接到MySQL数据库,我们就可以执行SQL查询语句了。在这个示例中,我们执行一个简单的SELECT语句来检索一条数据:
# 执行SELECT语句
cursor = cnx.cursor()
sql = “SELECT * FROM yourtable”
cursor.execute(sql)
步骤3:获取查询结果
执行查询后,我们需要从结果中获取数据。MySQL驱动程序提供了fetchall()方法来获取所有查询结果。这个方法返回一个元组列表,每个元组代表一条查询结果。
# 获取查询结果
results = cursor.fetchall()
步骤4:提取相应字段的值
最后,我们需要从查询结果中提取相应字段的值。假设我们的查询结果包含三个字段:id、name和age。我们可以使用索引来提取这些字段的值。
# 提取相应字段的值
for result in results:
id = result[0]
name = result[1]
age = result[2]
print(“ID: “, id)
print(“Name: “, name)
print(“Age: “, age)
完成以上步骤后,你将能够成功获取MySQL查询结果的相应字段值。