我们在客户端开发过程中总免不了和后端进行api对接,有时候需要对返回的数据格式进行调试,有时候每次运行客户端来发送请求,这个未免效率太低,这里就来介绍一个好用的工具–curl。
curl
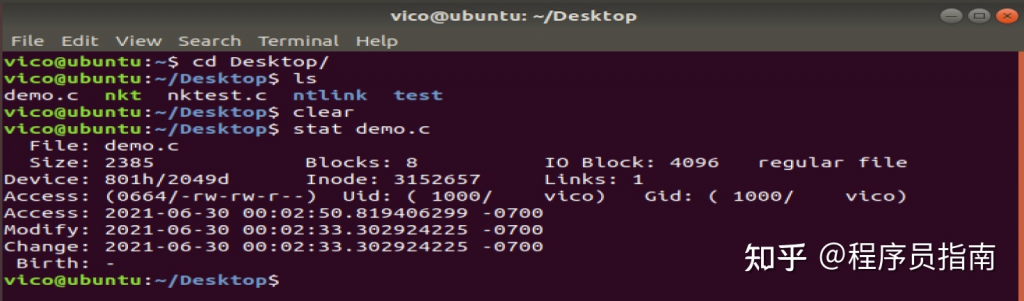
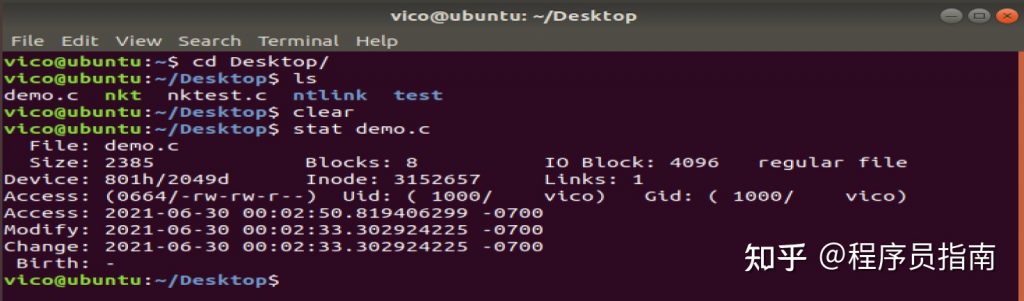
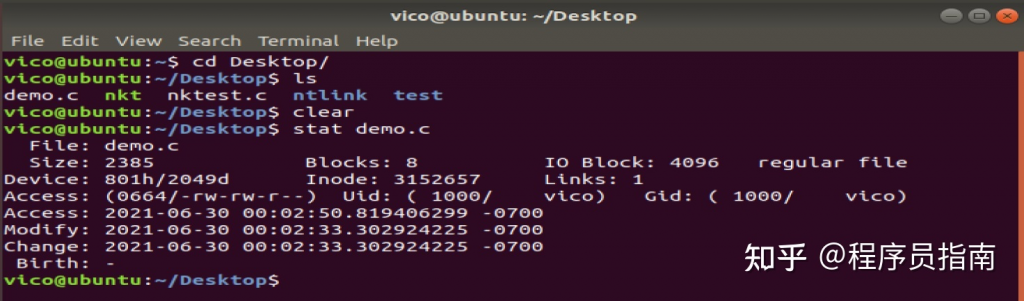
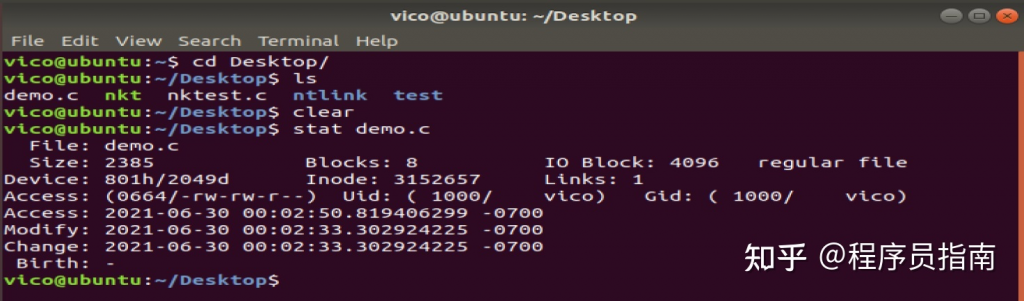
curl是一个向服务器传输数据的工具,它支持http、https、ftp、ftps、scp、sftp、tftp、telnet等协议,这里只针对http进行讲解一些常用的用法,具体安装请自行搜索。
打开百度
curl http://www.baidu.com
接着你就会看到百度的页面源代码输出。
如果要把这个网页保存下来,可以这样:
curl http://www.baidu.com > /tmp/baidu.html
你会看到一条进度条,然后源码就被重定向到了/tmp/baidu.html。
或者:
curl -o /tmp/baidu.html http://www.baidu.com
GET请求
默认直接请求一个url就是发出一个get请求,参数的话直接拼接在url里就好了,如
curl http://www.baidu.com/s?wd=curl
上述请求会上百度发起一条查询请求,参数是wd=url
POST请求
curl -d “name=test&page=1” http://www.baidu.com
-d 参数指定表单以POST的形式执行。
只展示Header
curl -I http://www.baidu.com
可以看到只返回一些header信息
HTTP/1.1 200 OK
显示通信过程
-v参数可以显示一次http通信的整个过程,包括端口连接和http request头信息
curl -v www.baidu.com
* Adding handle: conn: 0x7ffe4b003a00www.baidu.com port 80 (#0)www.baidu.com (61.135.169.125) port 80 (#0)www.baidu.com
如果你觉得上面的信息还不够,那么下面的命令可以查看更详细的通信过程。
curl –trace output.txt www.baidu.com
或者
curl –trace-ascii output.txt www.baidu.com
运行后,请打开output.txt文件查看。
HTTP方法
curl默认的HTTP方法是GET,使用-X参数可以支持其他动词。
curl -X POST www.example.com
curl -X DELETE www.example.com
Referer字段
有时你需要在http request头信息中,提供一个referer字段,表示你是从哪里跳转过来的。
curl –referer http://www.example.com http://www.example.com
User Agent字段
这个字段是用来表示客户端的设备信息。服务器有时会根据这个字段,针对不同设备,返回不同格式的网页,比如手机版和桌面版。
iPhone4的User Agent是
Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_0 like Mac OS X; en-us) AppleWebKit/532.9 (KHTML, like Gecko) Version/4.0.5 Mobile/8A293 Safari/6531.22.7
curl可以这样模拟:
curl –user-agent “[User Agent]” [URL]
增加头信息
有时需要在http request之中,自行增加一个头信息。–header参数就可以起到这个作用。
curl –header “Content-Type:application/json” http://example.com
来自 <http://stormzhang.com/devtools/2014/11/07/use-curl-debug/ >
-H, —header LINE Custom header to pass to server (H)
-d, —data DATA HTTP POST data (H)
示例命令
1 curl -H “Content-Type: application/json” -d ‘{“object_kind”:”merge_request”,”object_attributes”:{“id”:22,”target_branch”:”master”,”source_branch”:”master”,”source_project_id”:57,”author_id”:9,”assignee_id”:null,”title”:”Master Title”,”created_at”:”2014-07-02T02:31:20.000Z”,”updated_at”:”2014-07-02T02:36:33.008Z”,”milestone_id”:null,”state”:”closed”,”merge_status”:”unchecked”,”target_project_id”:55,”iid”:7,”description”:”description_content”}}’ http://10.0.6.122:9002/merge_request
来自 <https://cloud.tencent.com/developer/article/1328118 >
curl -v -H “Content-Type:application/json” \
-H “Authorization:Basic Y2xpZW50Q3JlZGVudGlhbHNJZDpzZWNyZXQ=” \
-X POST http://172.16.5.172:3396/crm/oauth/token?grant_type=client_credentials
请求soup
curl -X POST -d @testrequest.xml \
–header “Content-Type:application/json” \
http://localhost:8080/services/xxxxService
testrequest.xml
<soapenv:Envelope xmlns:soapenv=”http://schemas.xmlsoap.org/soap/envelope/” xmlns:ent=”http://entity.xxx.com”>
<soapenv:Header/>
<soapenv:Body>
<ent:getTableData>
<!–Optional:–>
<ent:oaUsername>zhangsan</ent:oaUsername>
</ent:getTableData>
</soapenv:Body>
</soapenv:Envelope>